

Introduction
Why Traditional Valuation Fails AI Startups
By Hindol Datta/ July 12, 2025
Breaks down how traditional DCF or comp-based methods fail to capture GenAI dynamics and proposes new value creation metrics
Beyond DCF and Comps Toward a Valuation Language for Intelligence
Over twenty-five years as a finance leader in cybersecurity, SaaS, logistics, and operations, I have seen many valuation models used to assess startup potential. At BeyondID and logistics firms I have recently helped, I built predictive models, operating plans, and financial strategies that captured real margins, growth, and capital leverage. When evaluating AI startups, including those influenced by the rapid shifts in OpenAI valuation, I observe that traditional valuation frameworks such as DCF models and public comparables struggle to describe value creation in generative AI accurately. AI consultants and financial strategists alike now face a new challenge: Generative AI and intelligence-driven startups do not just execute they learn, adapt, and improve over time, building competitive advantage through data, model depth, domain expertise, and agent design.
To value AI native companies correctly, we must go beyond revenue multiples and margin forecasts. We must treat intelligence, model-driven revenue, cognitive leverage, explainability, and learning velocity as core value drivers.
Why Traditional DCF Struggles with AI Startups
DCF assumes future value flows from cash from operations, discounted back at a risk-adjusted rate. That works for steady businesses. But in GenAI startups, much of the future value flows from usage-driven learning, data compounding, platform extensibility, and model improvements. These do not map cleanly to revenue or EBITDA forecasts.
For example, in a Series B GenAI startup that I helped assess, I saw that monetized API fees were visible. But the strategic value was in the model that improved with every contract, capturing domain-specific clause negotiation behavior. Traditional DCF captured immediate cash but ignored the accumulating model performance and data advantage.
AI startups often burn cash not because they fail at operations but because they are investing in learning. That investment is not an expense so much as it is a cognitive asset. Traditional valuation penalizes that.
Comps Based Valuation Is a Mirage in a Hype Market
When metrics are immature or cash flows are negative, investors fall back on comparables. In AI, that is risky. Many comparables are inflated by hype or are not comparable at all. A horizontal tool is not the same as a domain-specific AI agent in compliance, legal, health, or logistics.
In one AI project I advised, I saw investors apply a high sales efficiency multiple while ignoring that each new customer improved the model. Marginal value per user increased over time. SaaS economics often assumes diminishing returns. But in many AI use cases, returns grow with the scale of data, usage, and domain training.
Comps are useful as benchmarks. But they hide where GenAI value is created: not just in the number of users acquired but in knowledge, model improvement, and domain specialization.
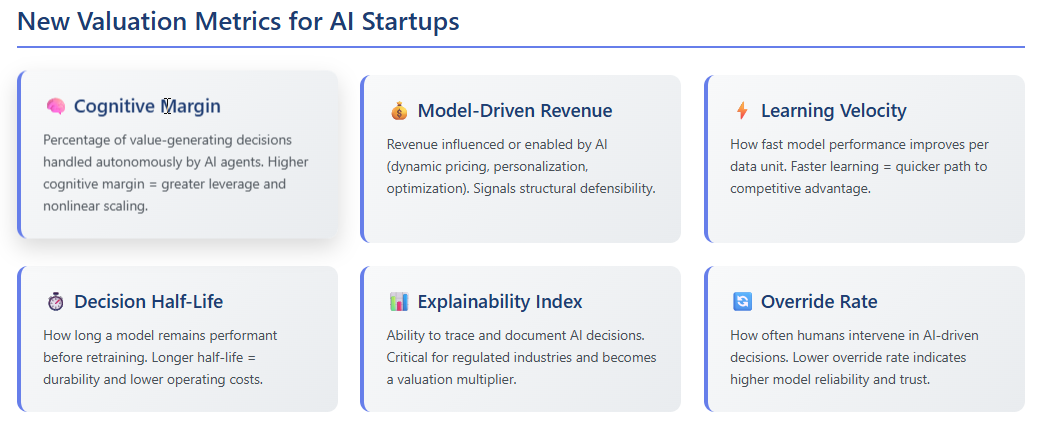
A New Framework Valuing Cognitive Leverage
To value AI startups well, I now use metrics that reflect the intelligence economy and model maturity. Here are metrics I use in internal valuation and investor conversations:
- Cognitive Margin
Measures the percentage of value-generating decisions handled autonomously by agents. If many underwriting, forecasting, and risk scoring tasks are model-initiated and accurate, the startup has leverage. Margin increases nonlinearly with model maturity.
- Model Driven Revenue
Quantifies how much revenue is influenced or directly enabled by AI agents. Includes dynamic pricing, personalization, or routing optimization—high model-driven revenue signals structural defensibility.
- Learning Velocity
Tracks how fast model performance improves per data unit. In my experience at BeyondID we saw that models trained on backlog data and new contracts improve forecasting accuracy much faster than just adding headcount in finance.
- Decision Half-Life
Measures how long a model remains performant before retraining is needed. A long half-life means durability and lower operating cost. Short half-life means technical debt.
- Explainability Index
Captures the ability to explain, trace, and document agent decisions. In regulated settings such as healthcare or compliance, this becomes not optional but core to valuation.
Agent Performance Metrics: What to Track
If the startup deploys intelligent agents for forecasting legal triage vendor scoring or customer personalization, I also track these operational proxies for intelligence scalability:
- Override rate: how often humans intervene in AI-driven decisions
- Drift rate: how performance degrades without retraining
- Time to adapt how fast the system learns a new domain or dataset
- Agent to analyst ratio: How many traditional tasks become automated
These are not vanity metrics. They show cognitive scale and value.
Case Study Forecasting AI in a B2B SaaS Company
At BeyondID, we replaced parts of the traditional forecasting engine with an AI agent trained on pipeline backlog, product usage, and marketing signals. That model reduced forecast variance by forty percent, detected GTM misalignment earlier, and freed up fifteen percent of finance team hours, under classic valuation that appeared only as cost savings or accuracy gains. But we treated it as systemic cognitive leverage.
We assigned value to the model via blended components, the replacement cost of building the model, the new discounted value of faster planning cycles, and revenue uplift from decision velocity. That raised our internal valuation and clarified for investors how the margin profile could improve nonlinearly.
The Role of Explainability in Value Creation
In sectors like compliance, cybersecurity, healthcare, risk, and logistics, explainability is more than a feature. It is a valuation multiplier. Black box models may predict well, but they cannot defend themselves under regulatory or audit scrutiny. Transparent models ease sales friction, accelerate compliance review, and open regulated markets.
In one logistics startup I worked with, explainable agent behavior in routing and freight optimization helped reduce customer contract risk and improved adoption among enterprises.
Boards Must Begin Asking Smarter Questions
CFOs and boards assessing AI startups, whether as investors or acquirers, must change their questions.
Instead of asking how fast you are growing, ask how your model improves with growth.
Instead of gross margin, ask what your cognitive margin is, how much cost structure is model-automated
Instead of LTV: CAC, ask how LTV improves as the model learns across customers
These shifts reframe AI startups not as execution bets but as learning systems with compounding intelligence.
Final Thought: From Models to Moats
Traditional valuation tools still matter, but when applied without adaptation, they undervalue what AI startups truly offer: systemic leverage, knowledge advantage, speed of iteration, and durable differentiators.
As capital becomes more selective, founders must be ready to explain value not just in revenue terms but in cognitive metrics. CFOs must become interpreters not just of financials but of intelligence architecture.
The next generation of market leaders will not necessarily be those with the most users or fastest revenue growth. They will be those with the best models, clearest agents, and most transparent governance.
Hindol Datta, CPA, CMA, CIA, brings 25+ years of progressive financial leadership across cybersecurity, SaaS, digital marketing, and manufacturing. Currently VP of Finance at BeyondID, he holds advanced certifications in accounting, data analytics (Georgia Tech), and operations management, with experience implementing revenue operations across global teams and managing over $150M in M&A transactions.





